論如何在技術圈爭論中一句話噎到對方:
哥們,是我創造了第一個大語言模型。
發言者 Jeremy Howard 為澳大利亞昆士蘭大學名譽教授、曾任 Kaggle 創始總裁和首席科學家,現 answer.ai 與 fast.ai 創始人。

事情的起因是有人質疑他最近的項目 llms.txt 在幫助大模型爬取互聯網信息上并沒太大作用,從而引發了這段爭論,迅速引起眾人圍觀。
聞訊而來的“賽博考古學家們”一番考據之后,發現第一個大語言模型這個說法還真有理有據:
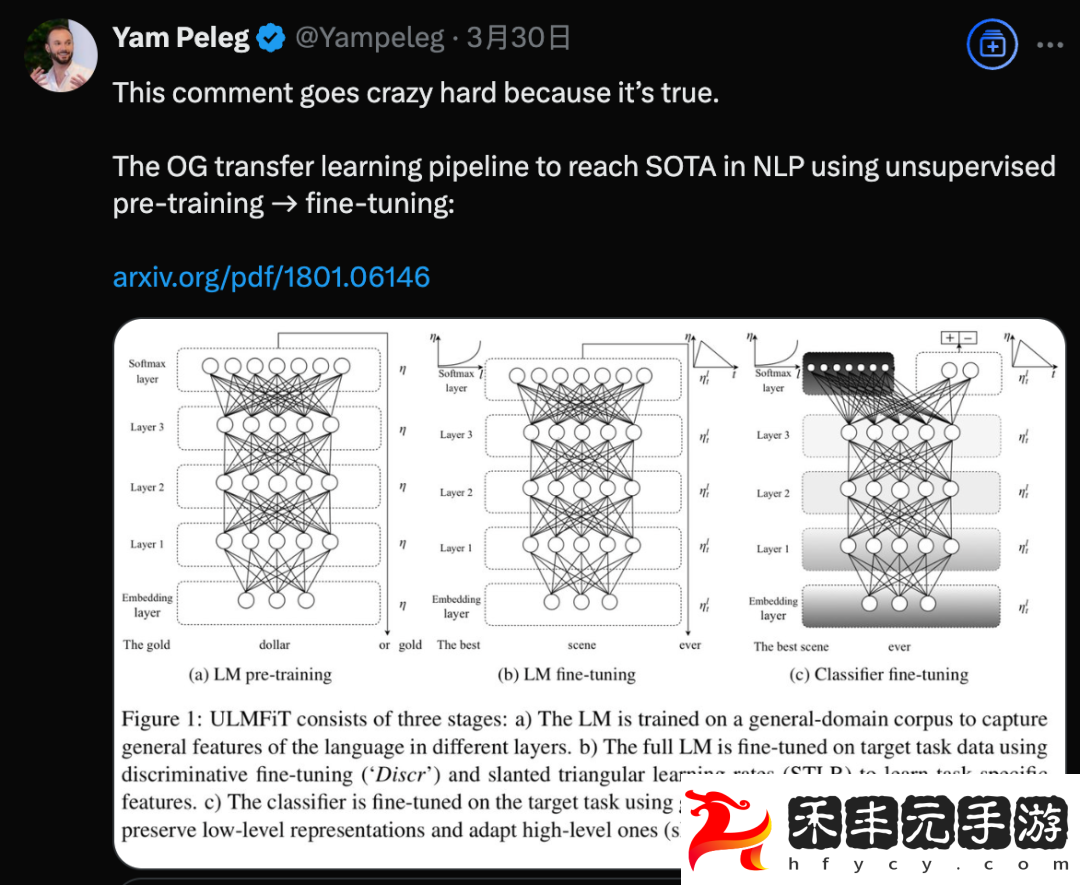
2018 年初,Jeremy Howard 發表的論文 ULMFiT,使用非監督預訓練-微調范式達到當時 NLP 領域的 SOTA。
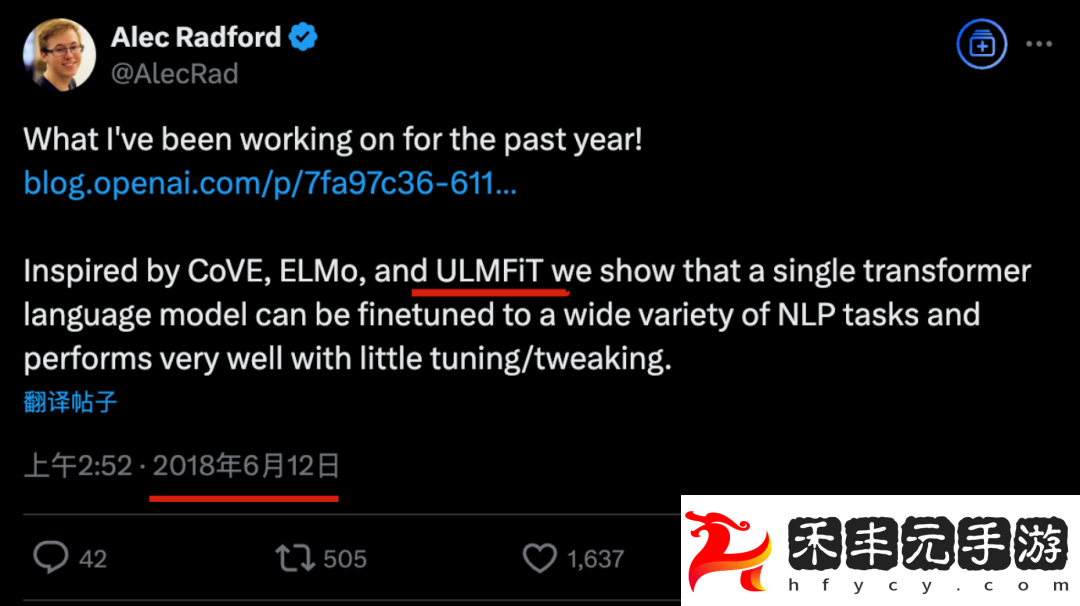
甚至 GPT-1 的一作 Alec Radford,在發表 GPT-1 時也公開承認過 ULMFiT 是靈感來源之一。
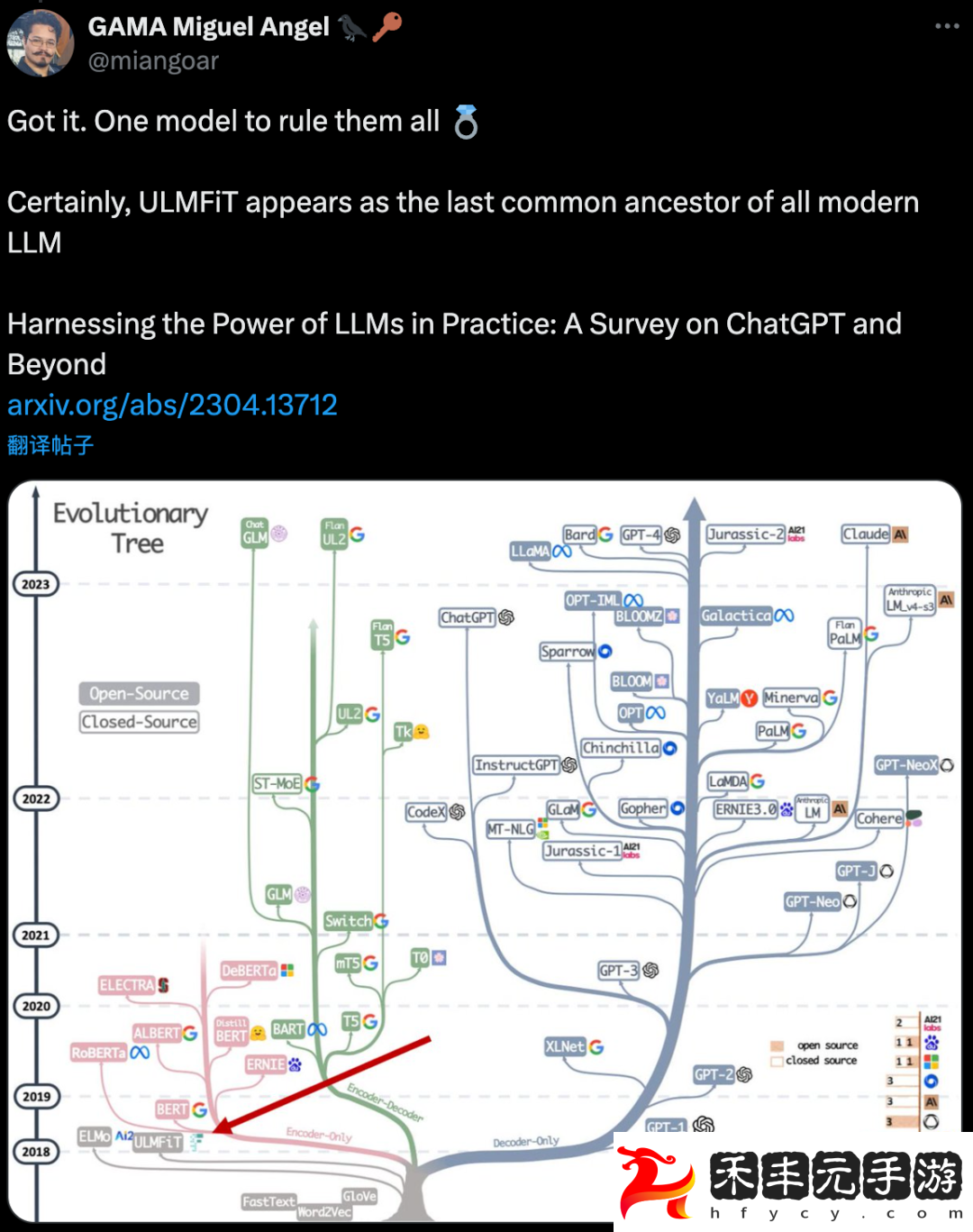
有人搬出綜述論文,指出從“遺傳學”視角看,ULMFiT 是所有現代大模型“最后的共同祖先”。
還有好事者軟件工程師 Jonathon Belotti,專門寫了一篇完整考據誰才是第一個大語言模型

大語言模型起源考據
首先來介紹一下 ULMFiT 這篇論文,入選 ACL 2018:
提出有效遷移學習方法,可應用于 NLP 領域的任何任務,并介紹了微調語言模型的關鍵技術,在六個文本分類任務上的表現明顯優于當時的 SOTA 方法,在大多數數據集上將錯誤率降低了 18-24%。此外,僅使用 100 個帶標簽的示例,它的性能就與在 100 倍以上數據上從頭開始訓練的模型性能相當。

那么 ULMFit 算不算第一個大語言模型呢?Jonathon Belotti 考據遵循這樣的思路:
首先找一個大家都公認肯定算大語言模型的成果,GPT-1 肯定符合這個標準。
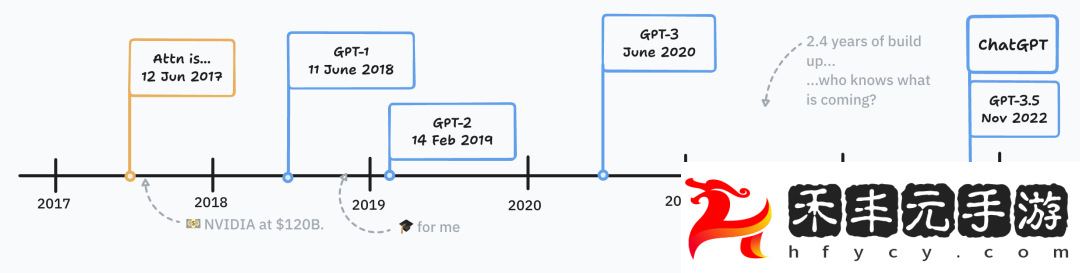
再從 GPT-1 和后續 GPT-2、GPT-3 中提取一個模型成為成為大語言模型的標準:
首先要是一個語言模型,根據輸入預測人類書面語言的組成部分,不一定是單詞,而是 token
核心方法是自監督訓練,數據集是未標記的文本,與此前特定于任務的數據集有很大不同
模型的行為是預測下一個 token
能適應新的任務:不需要架構修改,就有 few-shot 甚至 one-shot 能力
通用性:可以先進的性能執行各種文本任務,包括分類、問答、解析等
接下來分析 GPT-1 引用的幾個重要模型:原版 Transformer,CoVe,ELMo 和 ULMFiT。
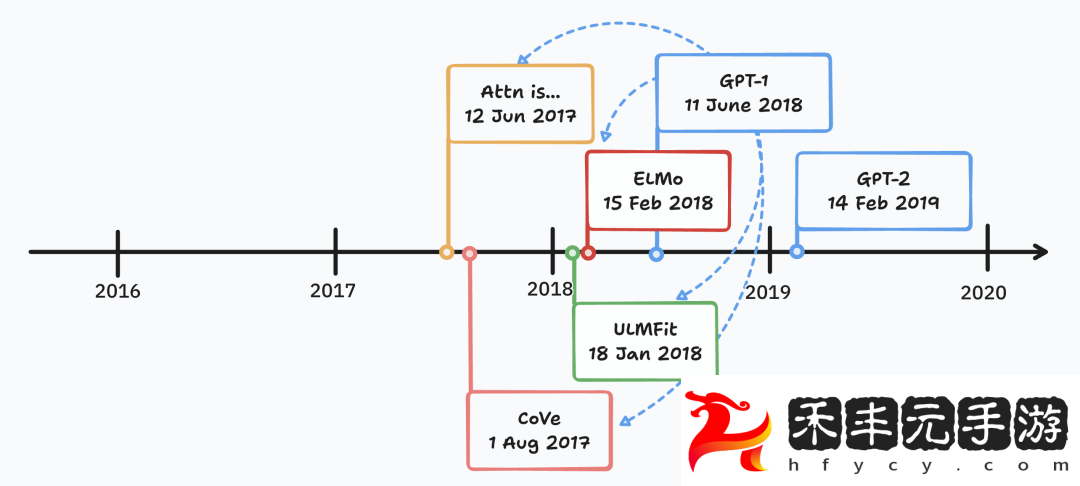
Transformer 雖然是現代主流大模型的架構基礎,但原版只用于機器翻譯任務,還不夠通用。同時非 Transformer 架構如 LSTM、Mamba 甚至 Diffusion 也可被視作大型語言模型。
CoVE 提出了語境化詞向量,是遷移學習領域的一項重要創新,但它通過監督學習訓練(英語翻譯德語)創建向量,不符合自監督學習的條件。
ELMo 使用了自監督預訓練和監督微調范式,但在 few-shot 能力上還差點意思。
